GCP-Recommendation-systems-with-TensorFlow
Practical code for deploying Recommendation systems on Google Cloud Platform
Project maintained by Sylar257 Hosted on GitHub Pages — Theme by mattgraham
GCP Recommendation systems with TensorFlow
Introduction: An overview of recommendation systems
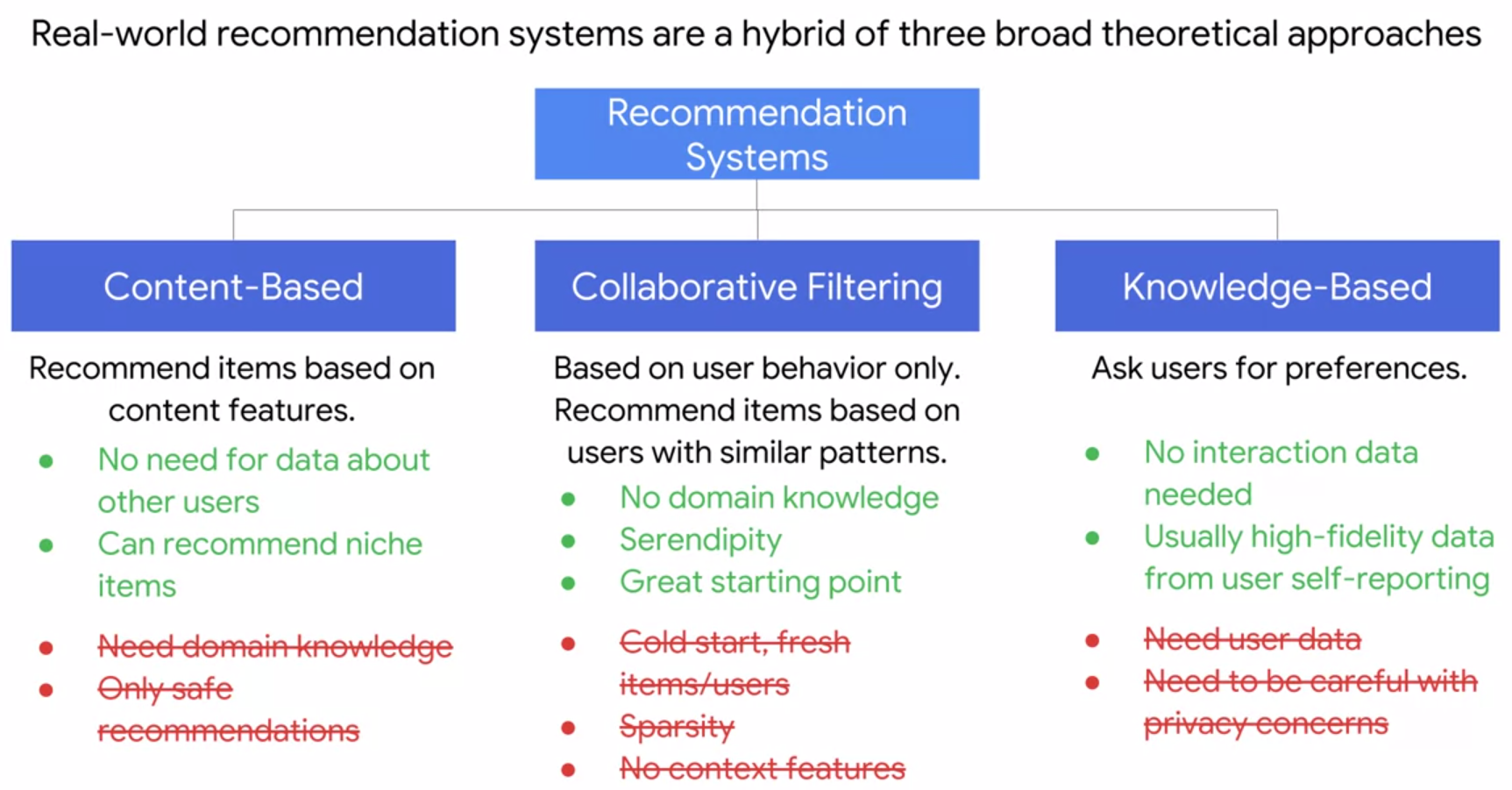
Content-based Filtering: Recommend items based on content features
Collaborative Filtering: Based on user behavior only. Recommend items based users with similar patterns
Knowledge-Based: Ask users for preference
Hybrid Recommendation systems: Real-world recommendation systems are usually a hybrid of three broad theoretical approaches
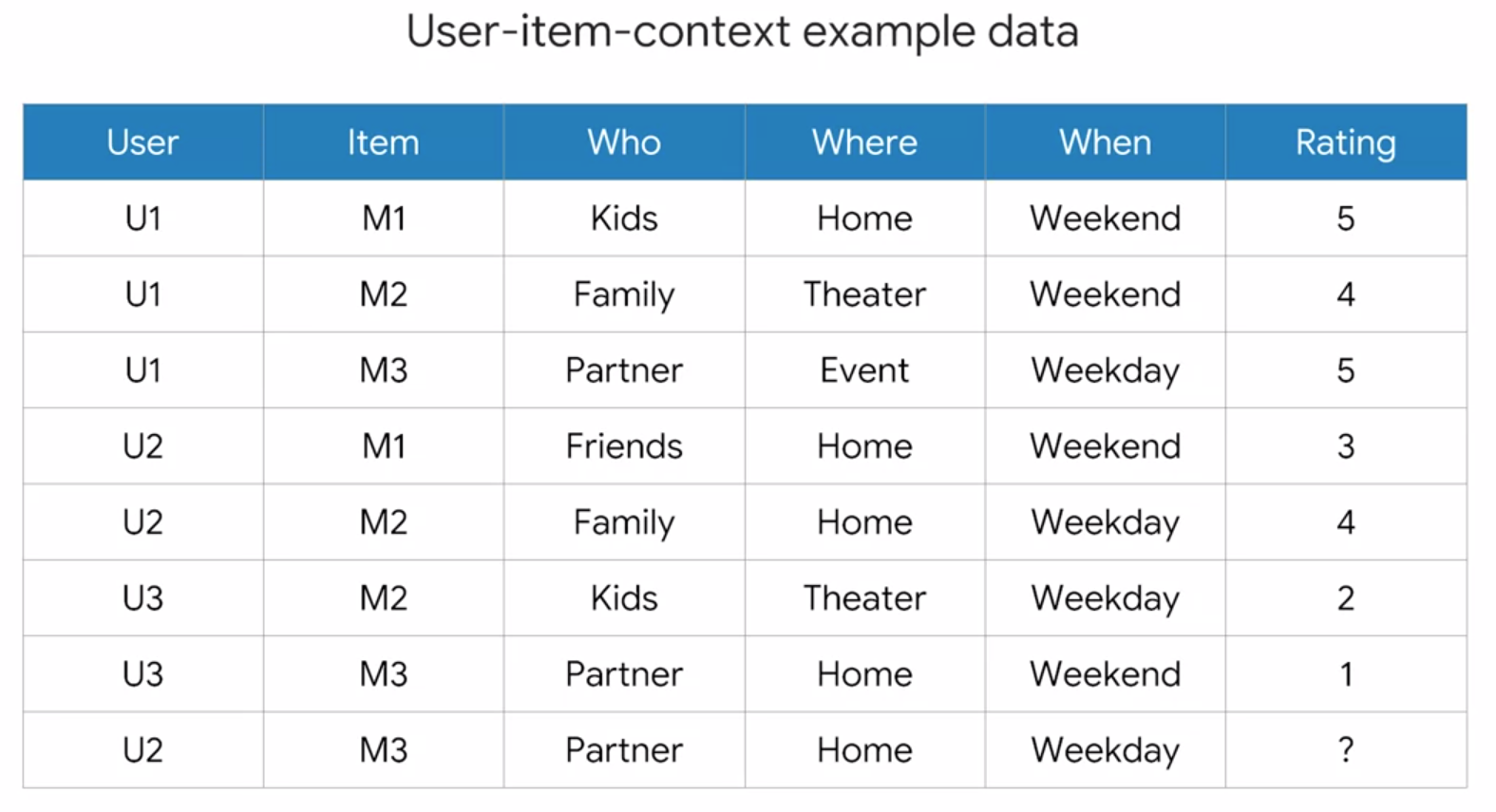
Context-aware recommendation systems(CARS): one more dimension considered for the context
Introduction
Recommendation systems are what behind the scenes that push YouTube videos to us that we actually find interesting.
However, Recommendation systems are not just about suggesting products to users. Sometimes they can be about suggesting users for products (this is often referred to as targeting).
Google Maps that suggests the route that avoids toll roads; smart reply suggest possible replies to email that we received are also Recommendation systems. It is about personalization for each individual user.
Option I:
Content-based system, we use the metadata about our products. (e.g. we know which movies are cartoons and which movies are sci-fi. Now, suppose we have a user who has seen and rated a few movie. Then we can recommend accordingly) Note that in this case, we have already segmented the category and know that corresponding attribute of each of our product.
There is no Machine Learning happening here.
Content-based filtering uses item features to recommend new items similar to what the user has liked in the past.
Option II
Collaborative Filtering, we have no metadata. Instead, we learn about item similarity and user similarity from the ratings data itself.
We usually separate the large matrix into user factors and item factors. Then, if we need to find whether a particular user will like a particular movie, it’s as simple as taking the row corresponding to the user and the column corresponding to the movie and multiplying them to get the predicted rating.
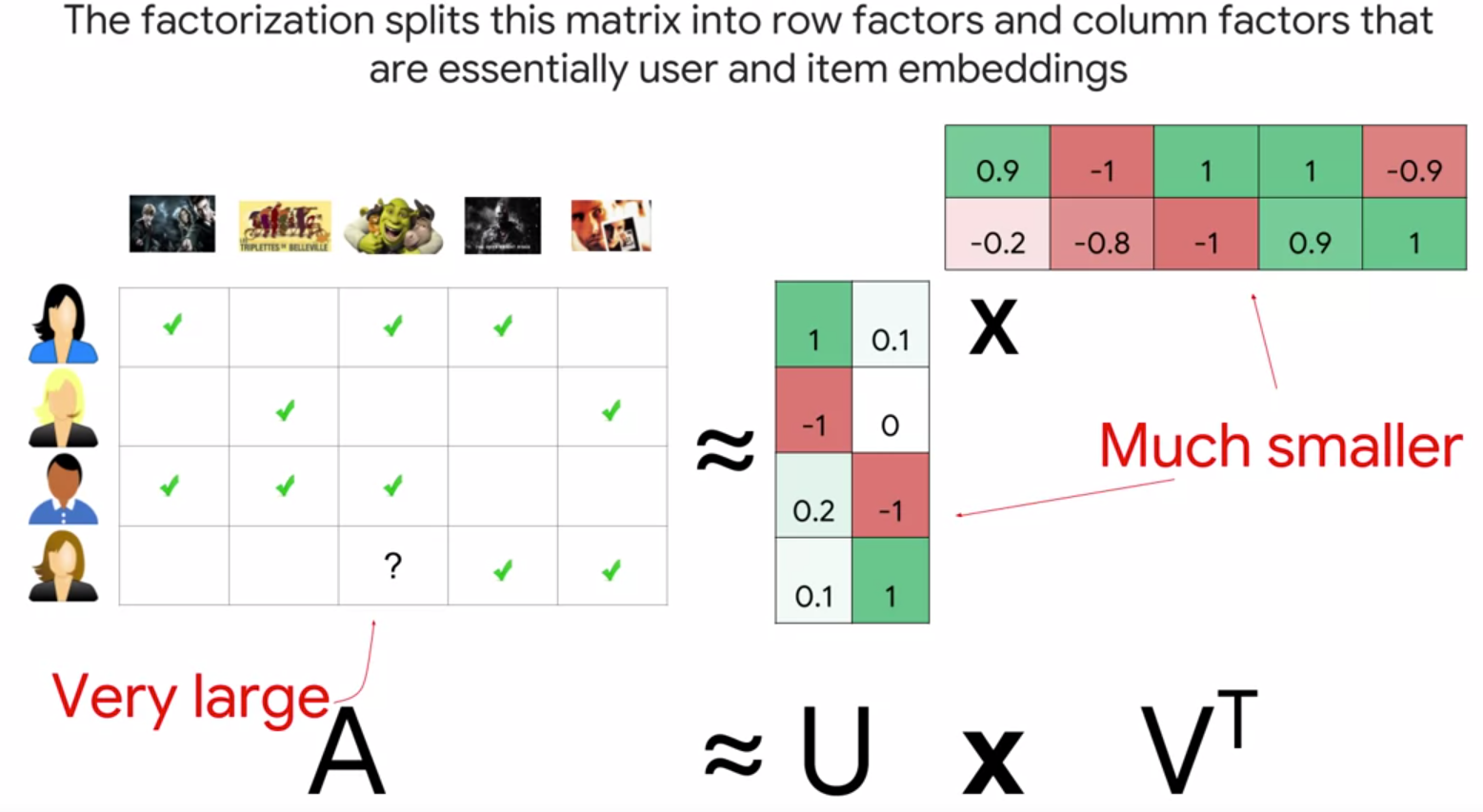
Collaborative Filtering uses similarities between users and items simultaneously to determine recommendations.
Option III
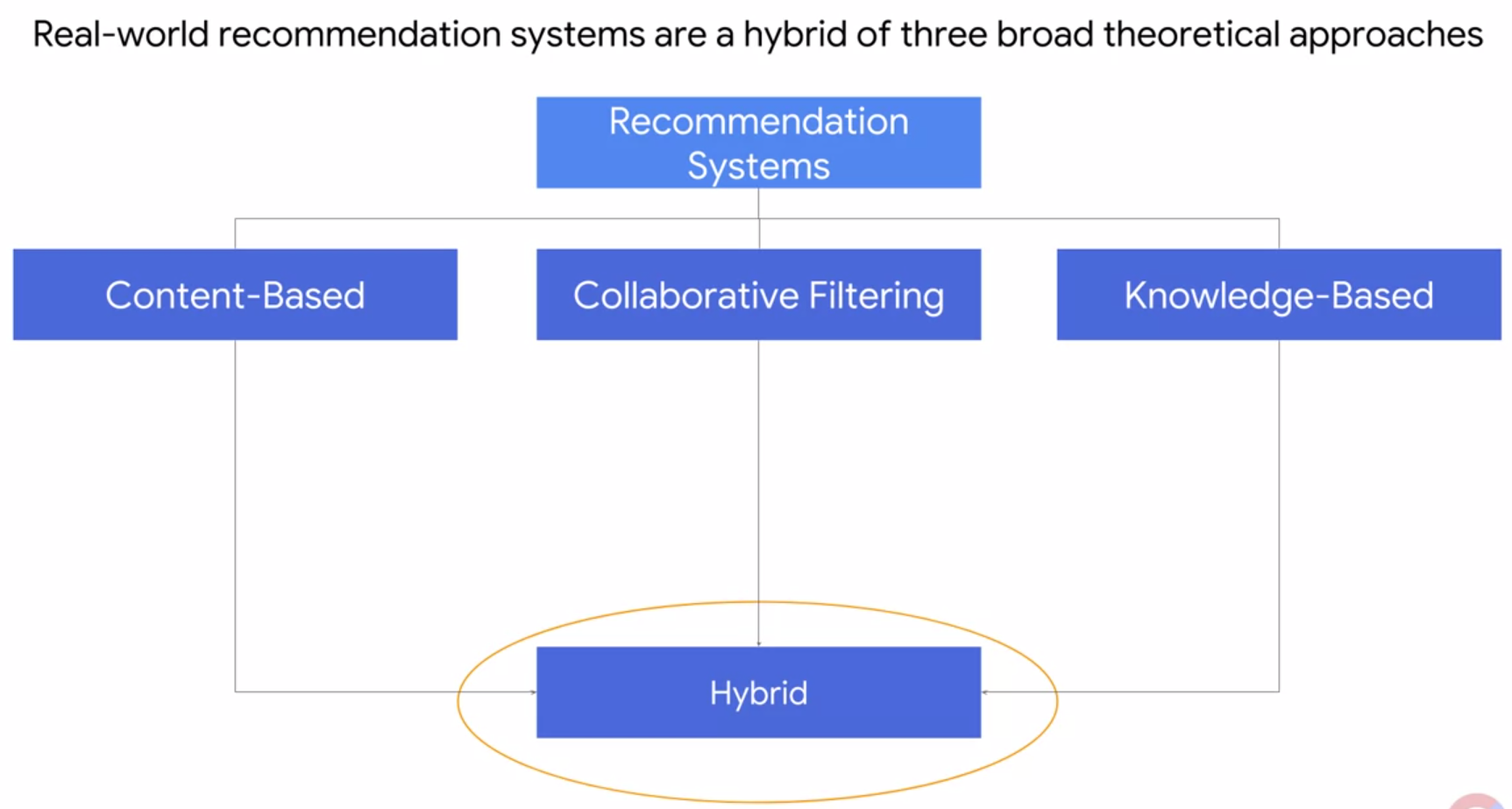
If we have both the meta-data and user interaction matrix, we can build a Hybrid system that overcomes most of individual shortcomings.
For example, we could develop a few recommenders and then use one or the other depending on the scenario. If a user has already rated a large number of items, perhaps we can rely on a collaborative filtering method. However, if the user has rated only a few items, we may instead prefer to use a content-based approach. This way, we can fully leverage the information we have about other users and their interactions with items in our database, to gain some insight into what we can recommend.
Of course, if we have no information about a user’s previous item interactions or we like any information about a given user, we may instead want to rely on a knowledge-based approach, and ask the user directly for their preferences via a survey before making recommendations. (this is why NetFlix asks you movies/shows you like when you create a new account)
Lastly, we can build an ensemble model based on all of three outcomes.
Option IV
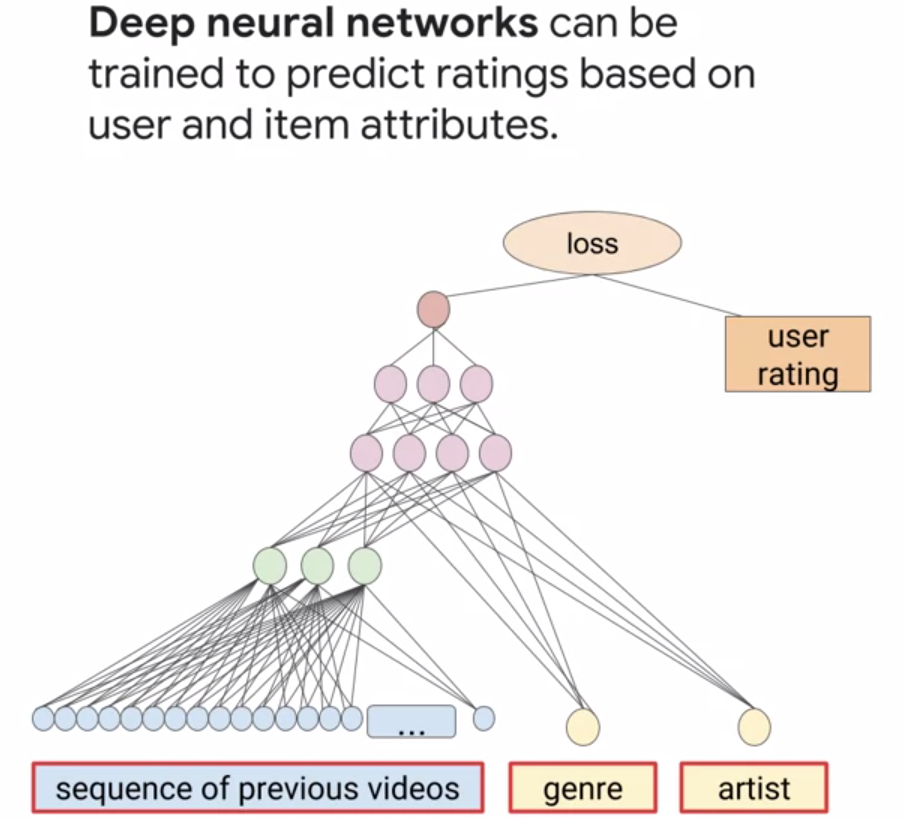
For example, suppose we wanted to recommend videos to our users, we could approach this from a deep learning point of view by taking attributes of the user’s behavior input, for example, a sequence of their previously watched videos embedded into some latent space, combined with video attributes, either genre or artists information for a given video.
Content-based_filtering
Content-based filtering uses item features to recommend new items that are similar to what the user has liked in the past.
We will look into:
- how to measure similarity of elements in an embedding space
- the mechanics of content-based recommendation systems
- build a content-based recommendation system
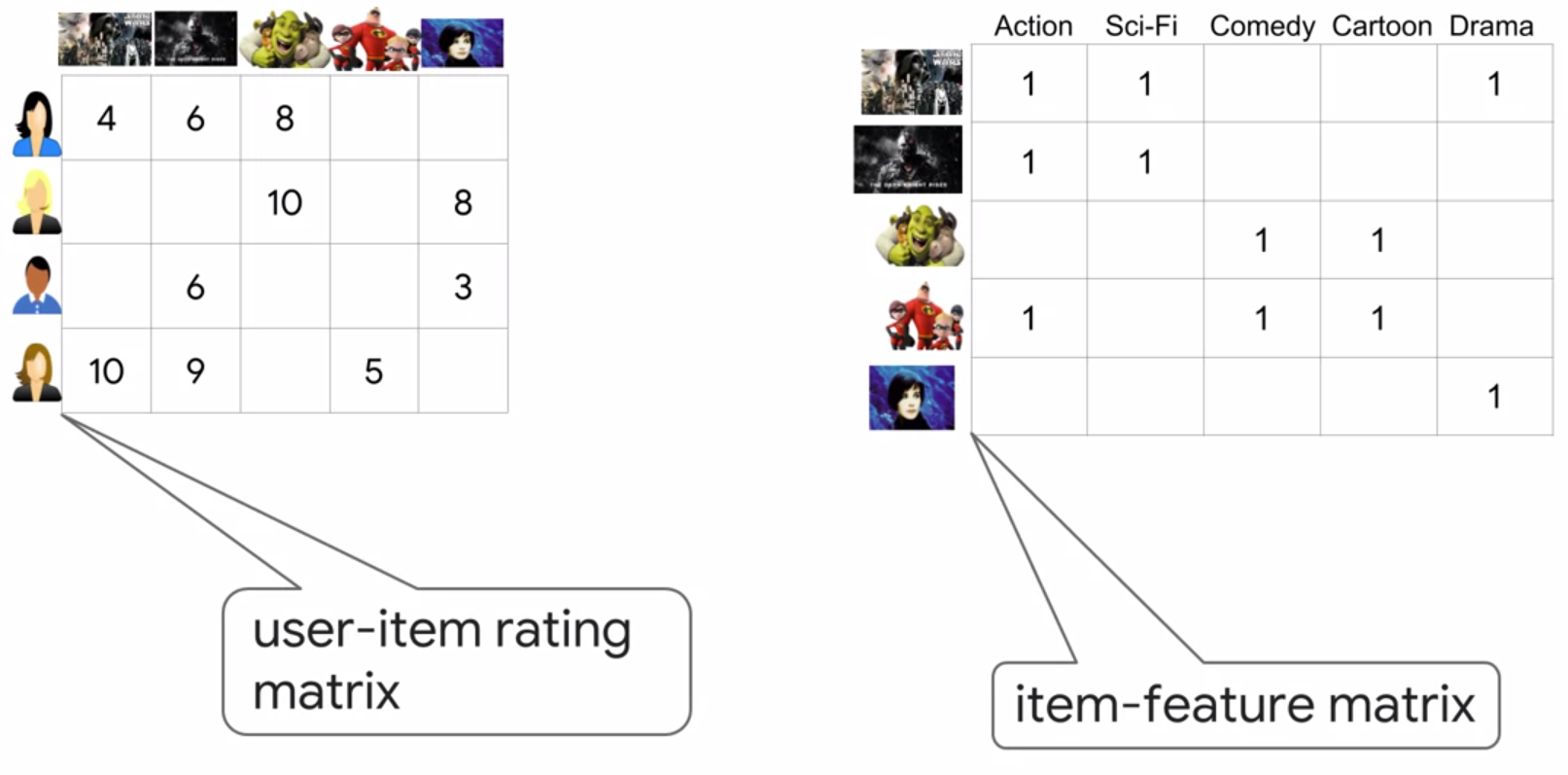

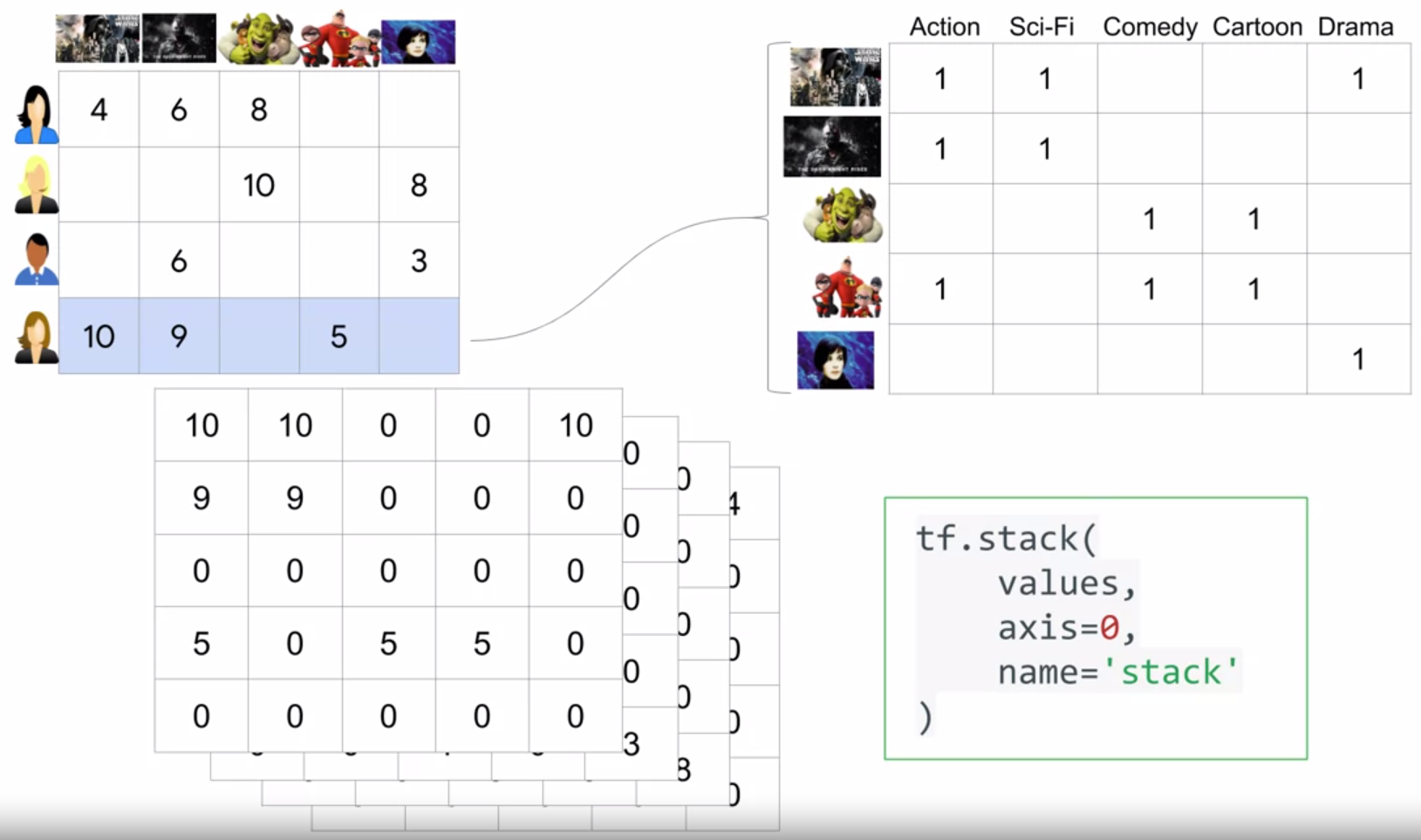
compute matrix for each user, then use tf.stack() to stack them together:

Sum across feature columns, and then normalize individually:
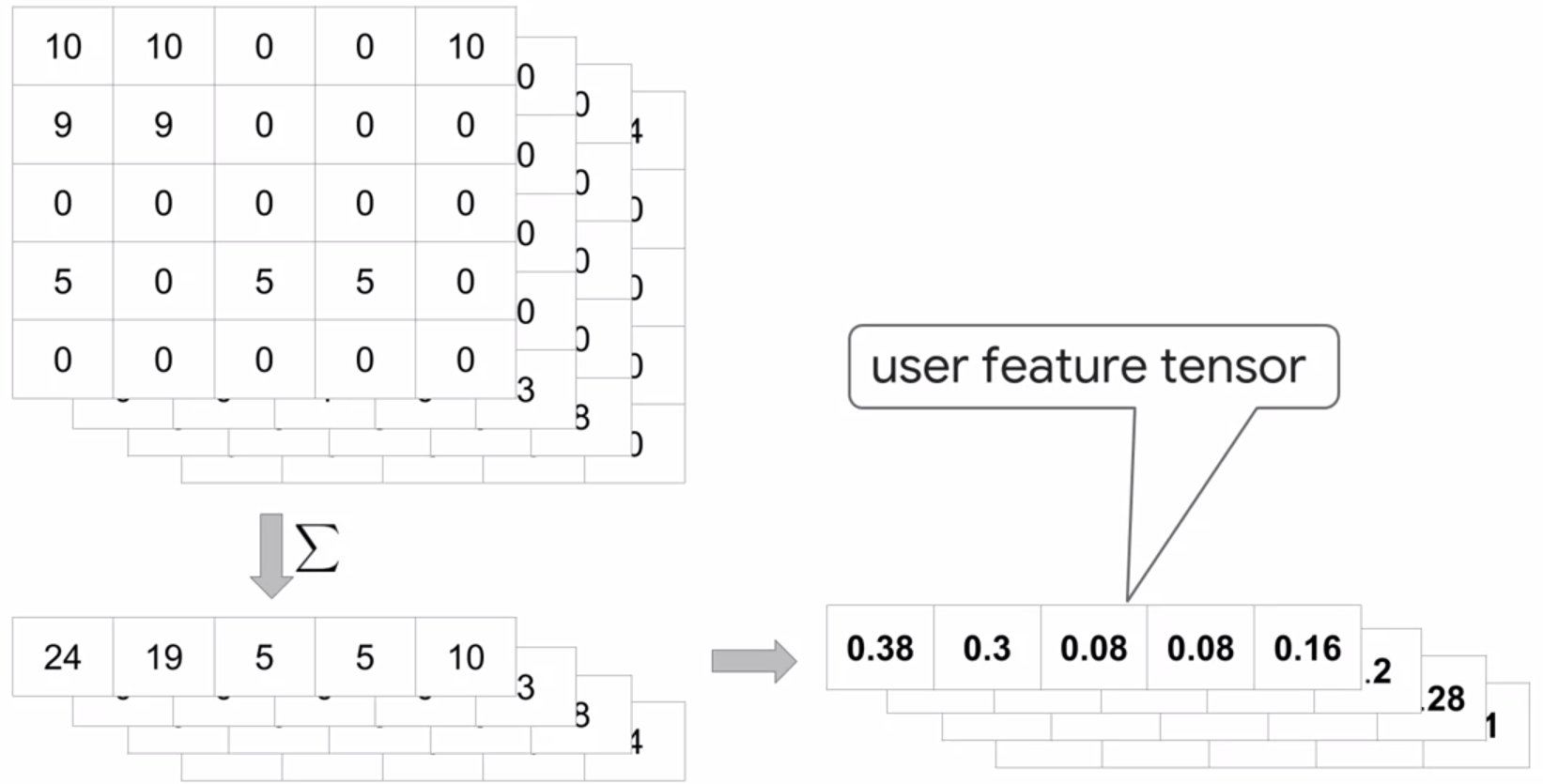

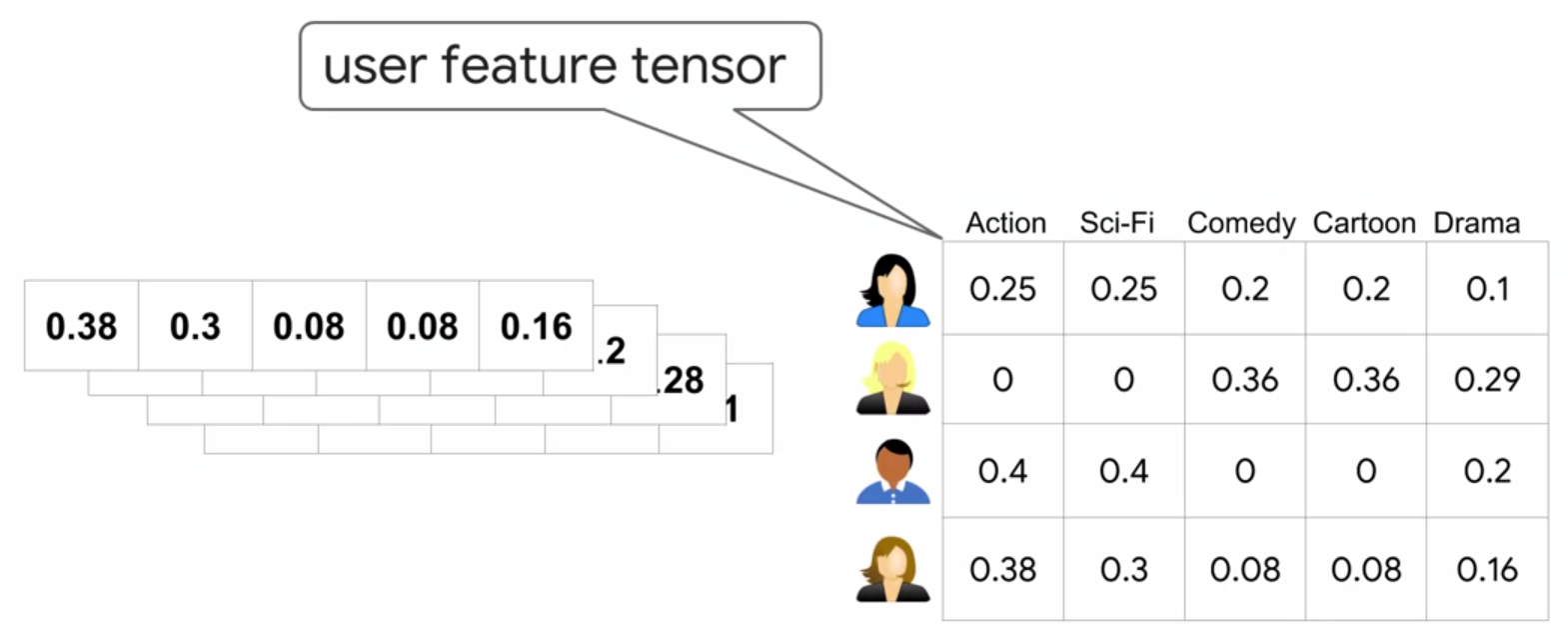
This results in a user feature tensor, where each row corresponds to a specific user feature vector:
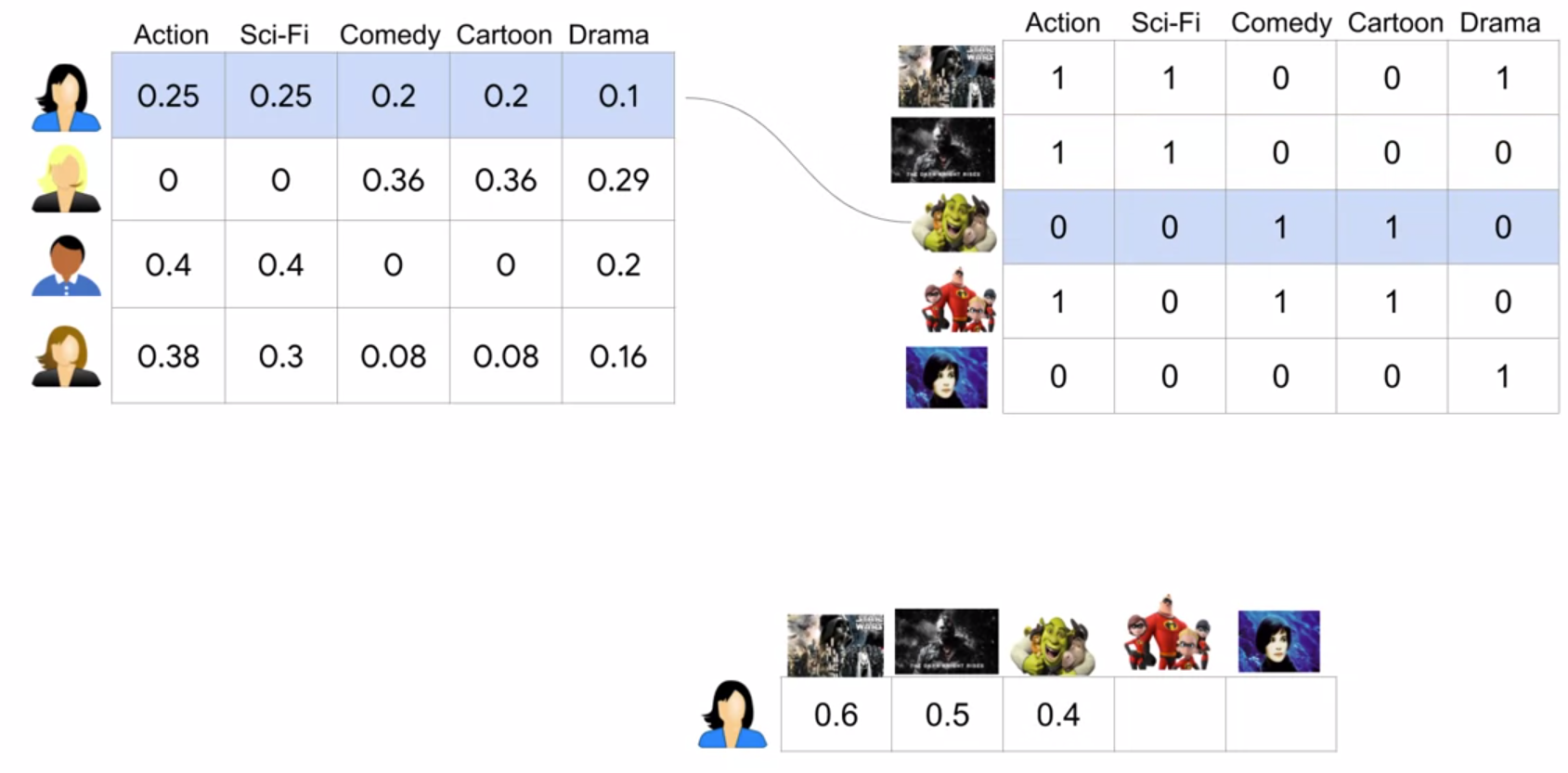
To find the inferred new movie rankings for our users, we compute the dot product between each user feature vector and each movie feature vector. In short, we’re seeing how similar each user is with respect to each movie as measured across these five feature dimensions:
Do the same thing for all other users:
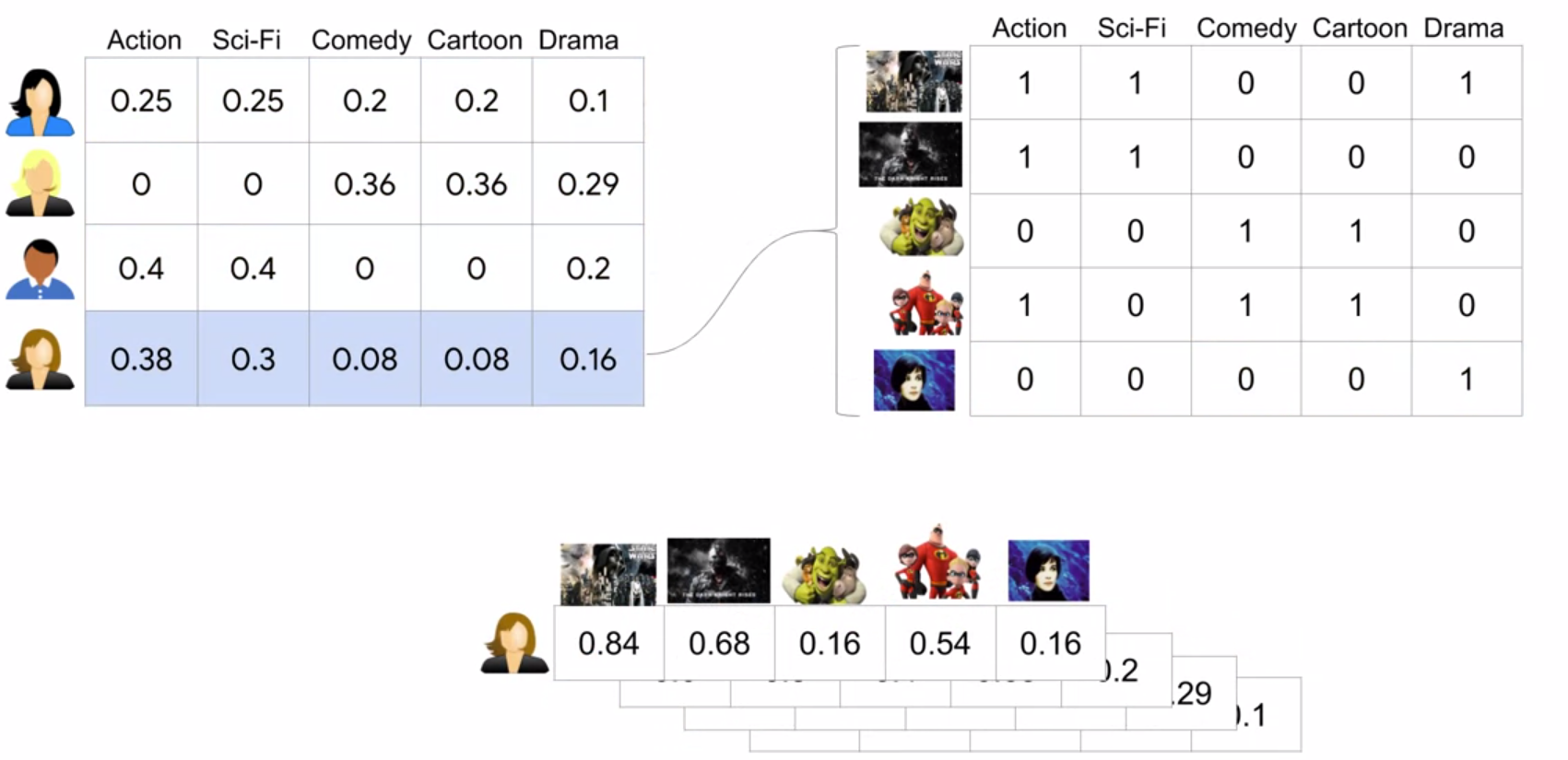
use tf.map_fn() to achieve this:

use tf.where() to focus only on the movies without rankings yet(new movies):

this brings us to here:
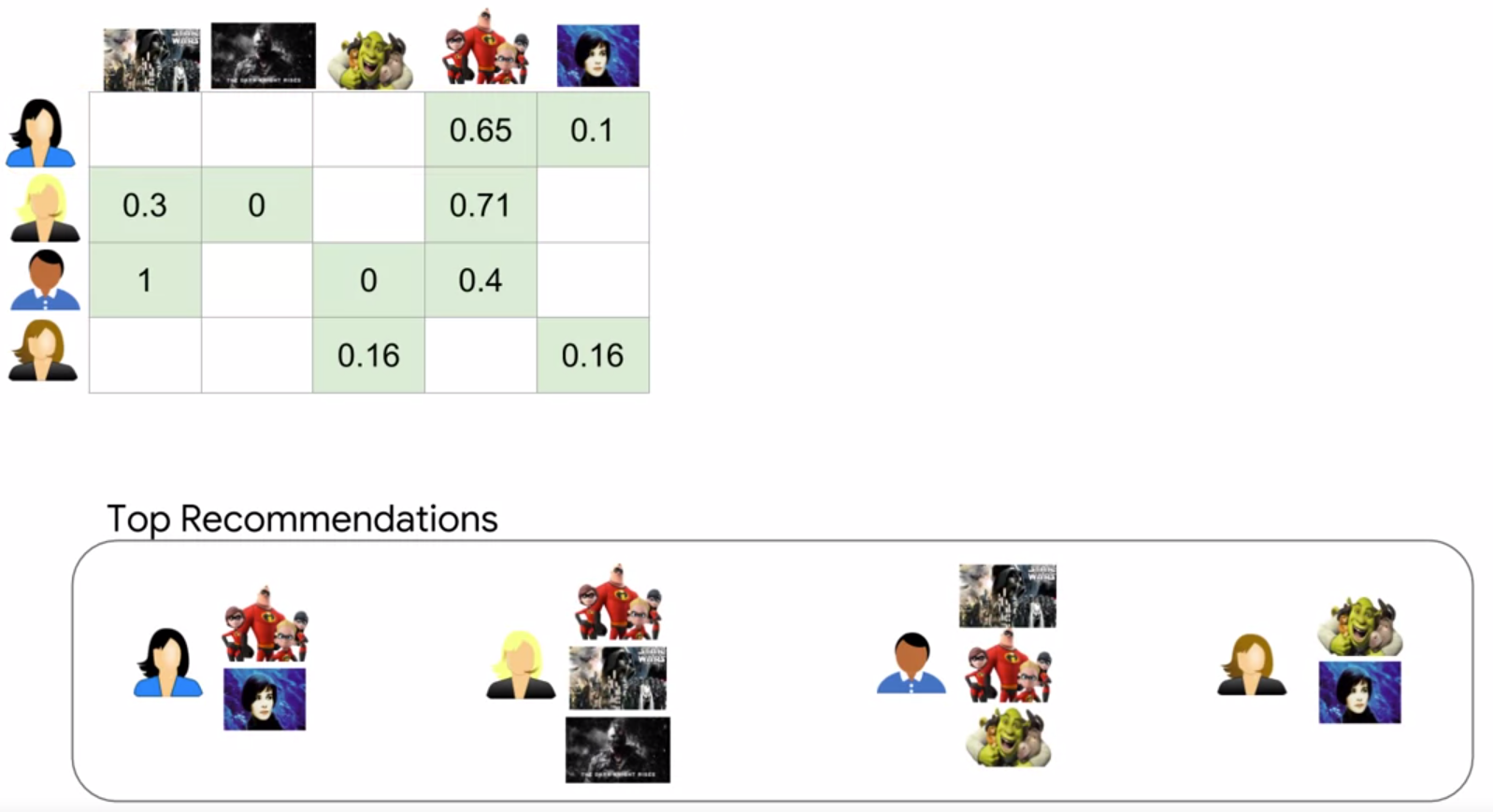
Collaborative_Filtering
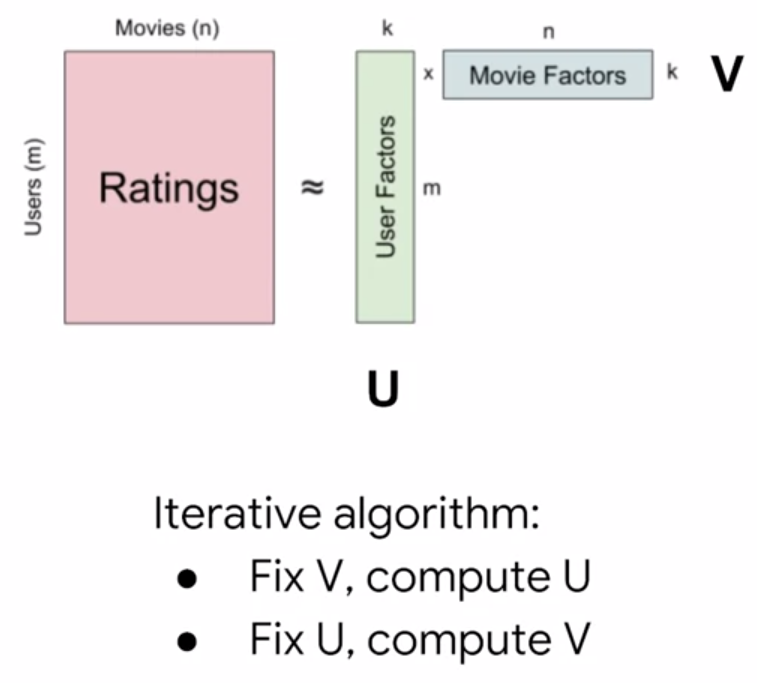
Content based recommendations used embedding spaces for items only, whereas for collaborative filtering we’re learning where users and items fit within a common embedding space along dimensions they have in common.
We can choose a number of dimensions to represent them in either using human derived features or using latent features that are under the hood of our preferences, which we’ll learn how to find very soon.
Each item has a vector within its embedding space that describes the items amount of expression of each dimension. Each user also has a vector within its embedding space that describes how strong their preference is for each dimension.
We don’t hand-engineer the feature embedding anymore
The embeddings can be learned from data.
Instead of defining the factors that we will assign values along our coordinate system, we will use the user item interaction data to learn the latent factors that best factorize the user item interaction matrix into a user factor embedding and item factor embedding.
The number of latent features(in this case it’s 2) is a hyperparameter that we can use as a knob for the tradeoff between more information compression and **more reconstruction error **from our approximated matrices.

We use Weighted Alternating least squares(WALS) to solve factorization and impute unwatched movies with low confidence score.
How does this works:
def training_input_fn():
features = {
INPUT_ROWS: tf.SparseTensor(...)
INPUT_COLs: tf.SparseTensor(...)
}
return features, None
There is no label as we are solving the two features based on interaction matrices
Implementing WALS in TensorFlow
The first notebook enables us to convert our data from warehouse to the user interaction matrix.
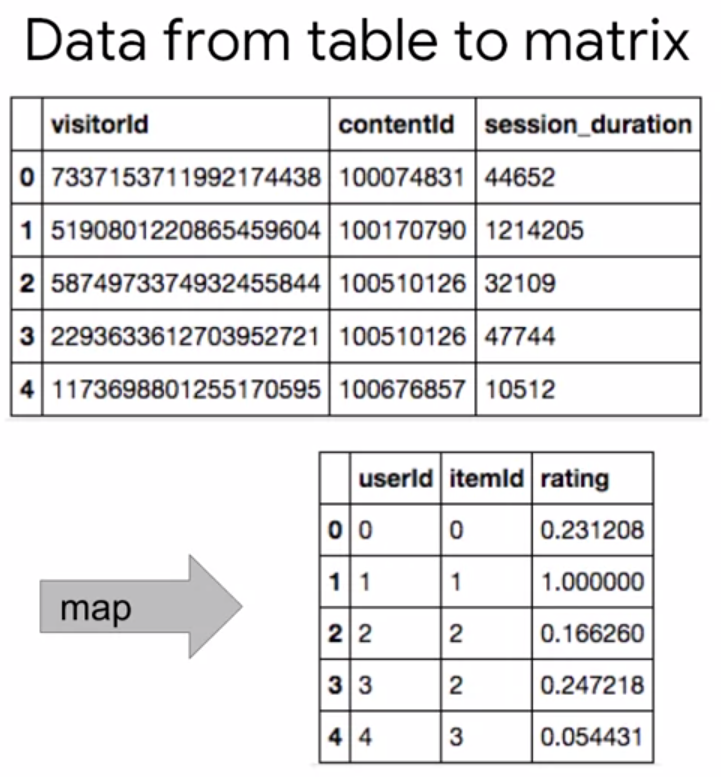
Next step is to apply tf.contrib.factorization.WALSMatrixFactorization. The algorithm is all setup, we just need to connect some piping, such as input_fn serving_input_fn and train_and_eval_loop.
Because WALS requires whole rows or columns, the data has to be preprocessed to provide SparseTensors of rows/columns.


After creating rows/columns, we use tf.contrib.learn. to construct factorization estimator:

let’s take a look into the train_input_fn and eval_input_fn:
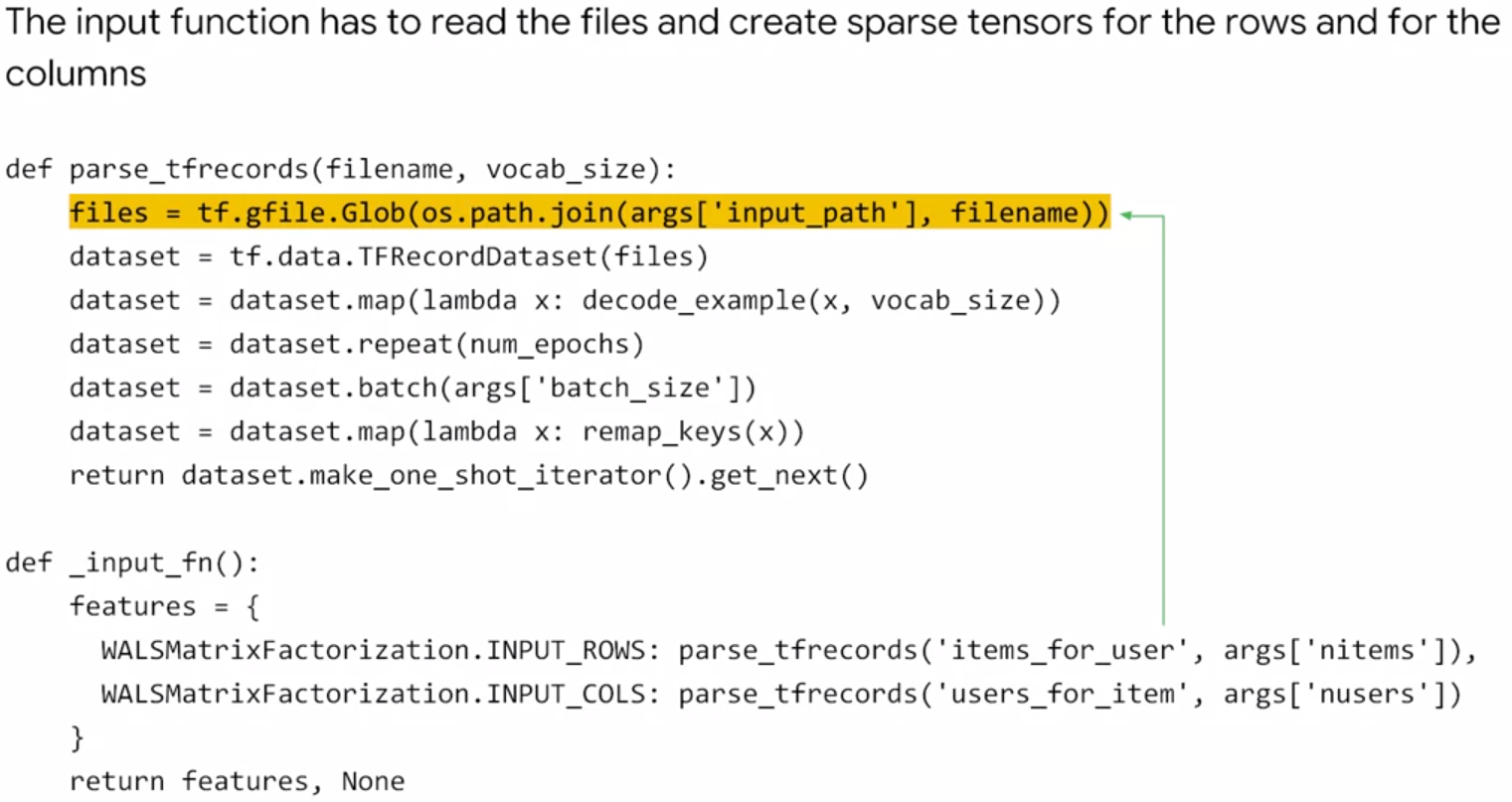
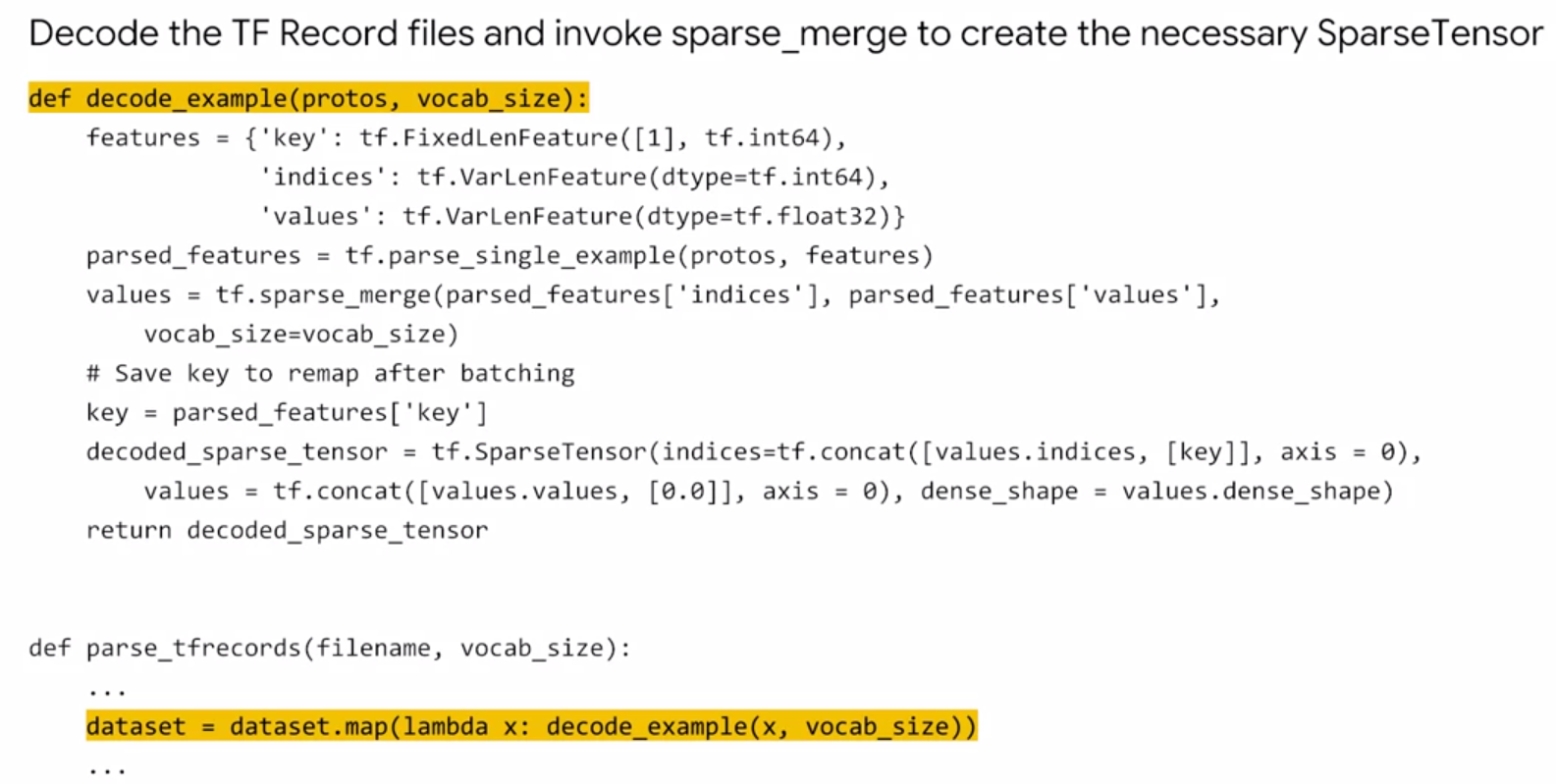
Instantiating a WALS Estimator
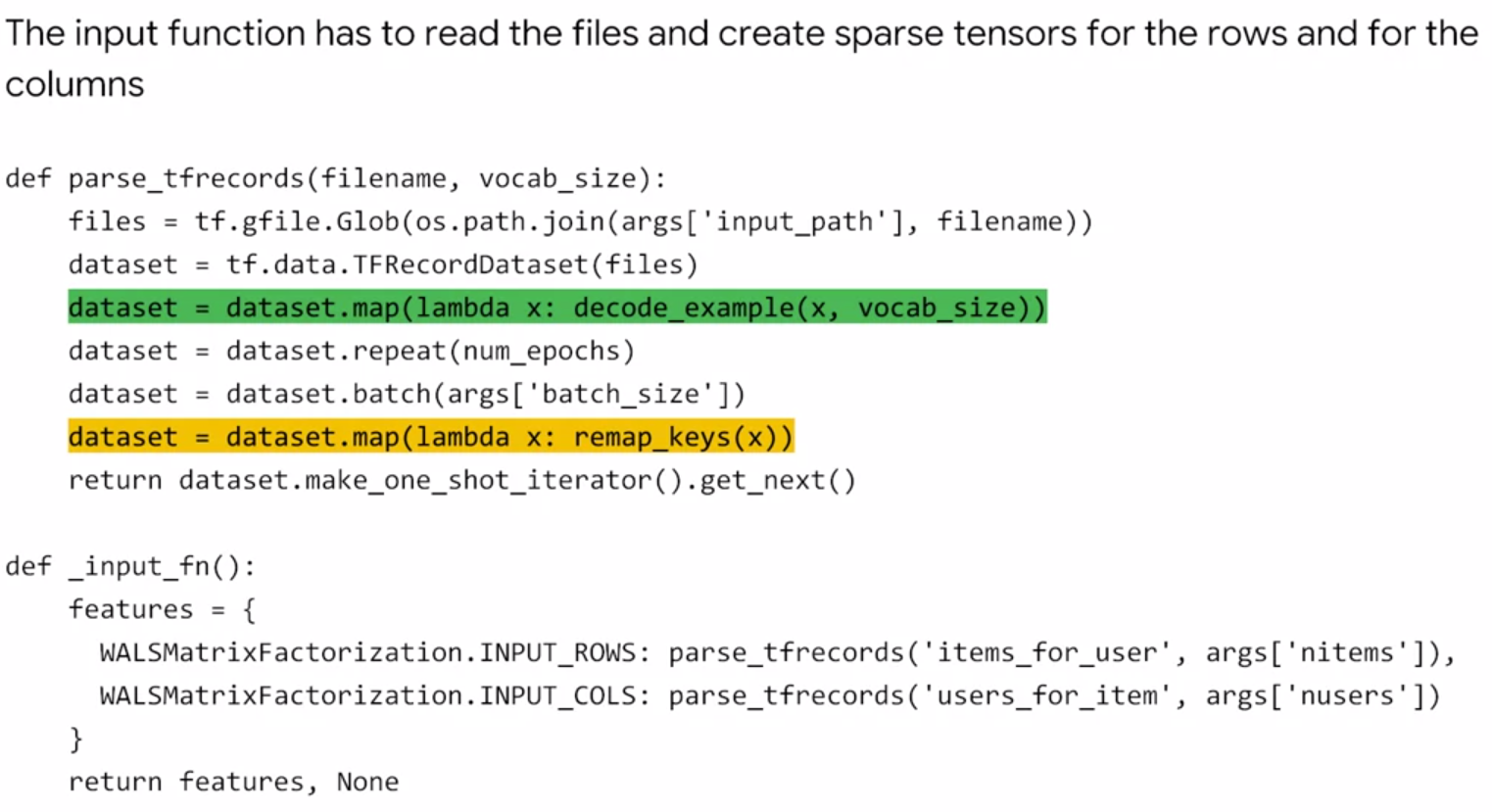

Next, create train_and_evaluate() loop wrapping around tf.contrib.factorization.WALSMatrixFactorization():

Issues with Collaborative Filtering
The cold start problem

Solution: a hybrid of content+collab
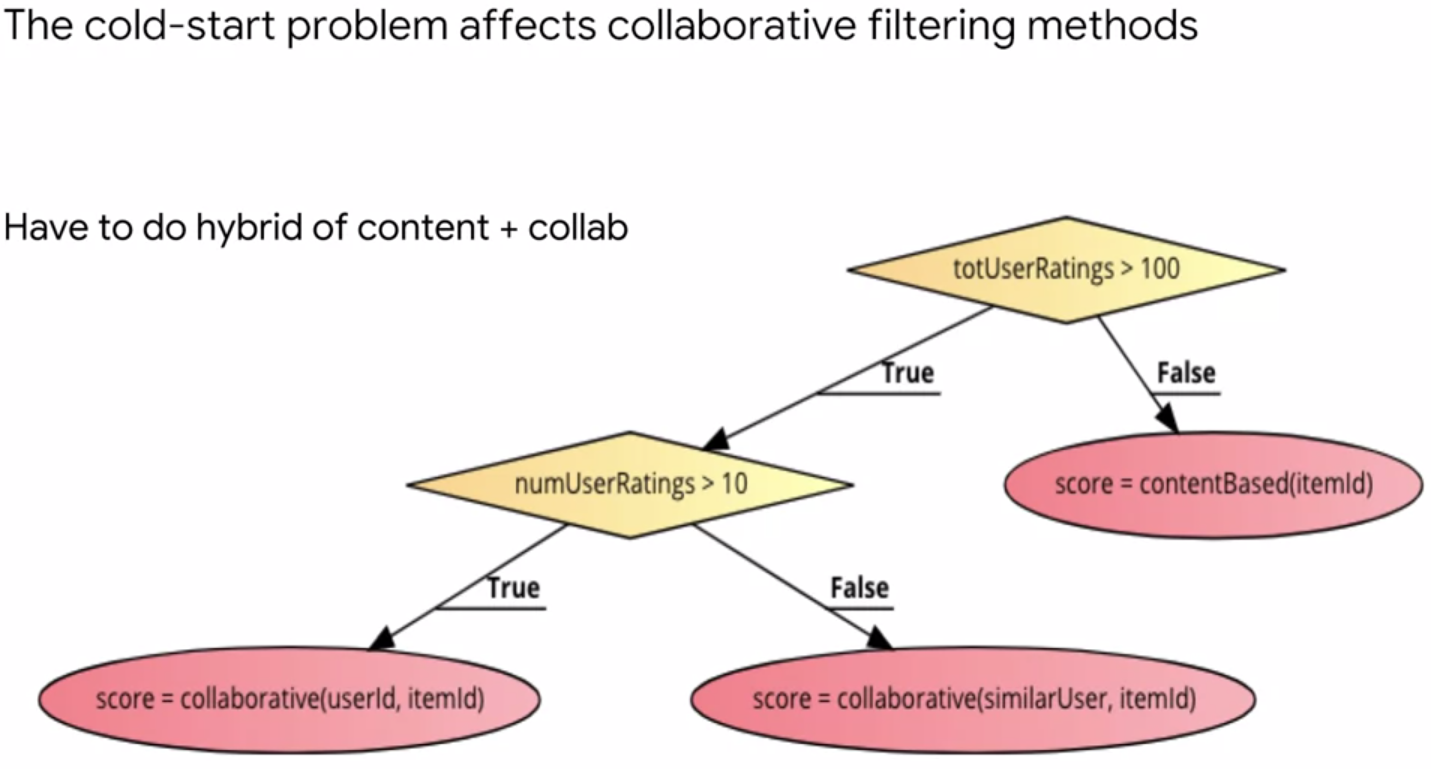
Hybrid_system
A simple way to create a hybrid model is to just take things from each of the models and combine them all in a neural network.
The idea is that the independent errors within each mile will cancel out, and we’ll have much better recommendations.
CARS

For example:
CARS algorithms:
- Contextual prefiltering
- Contextual postfiltering
- Contextual modeling
Contextual prefiltering
user x item x context ==> Rating
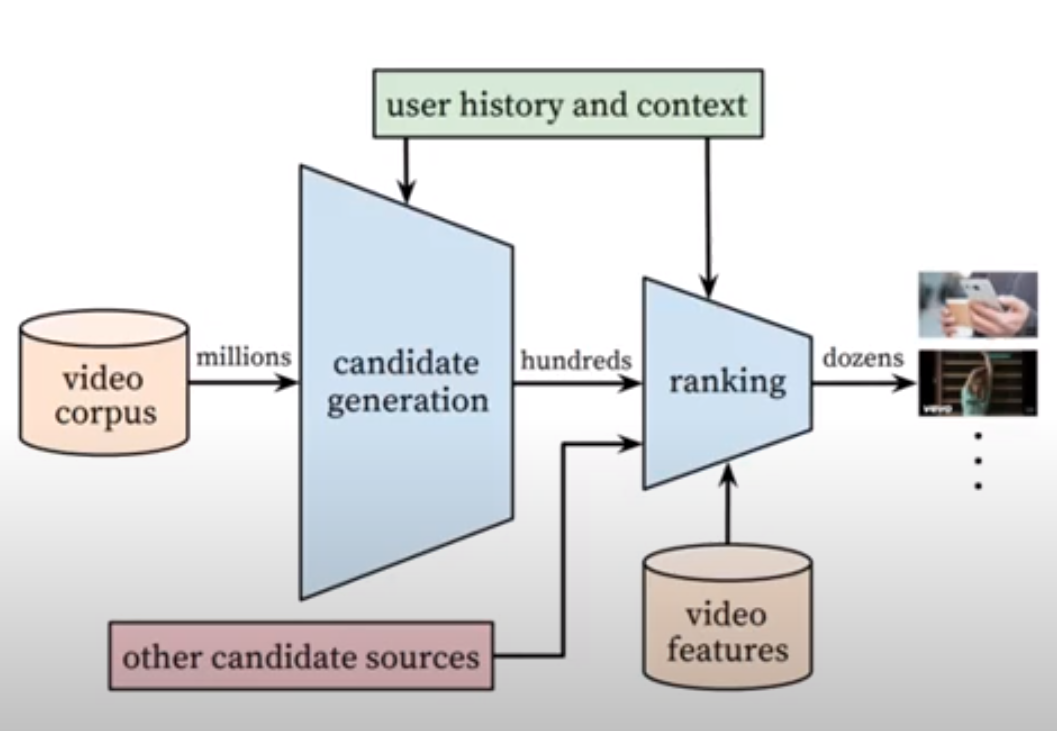
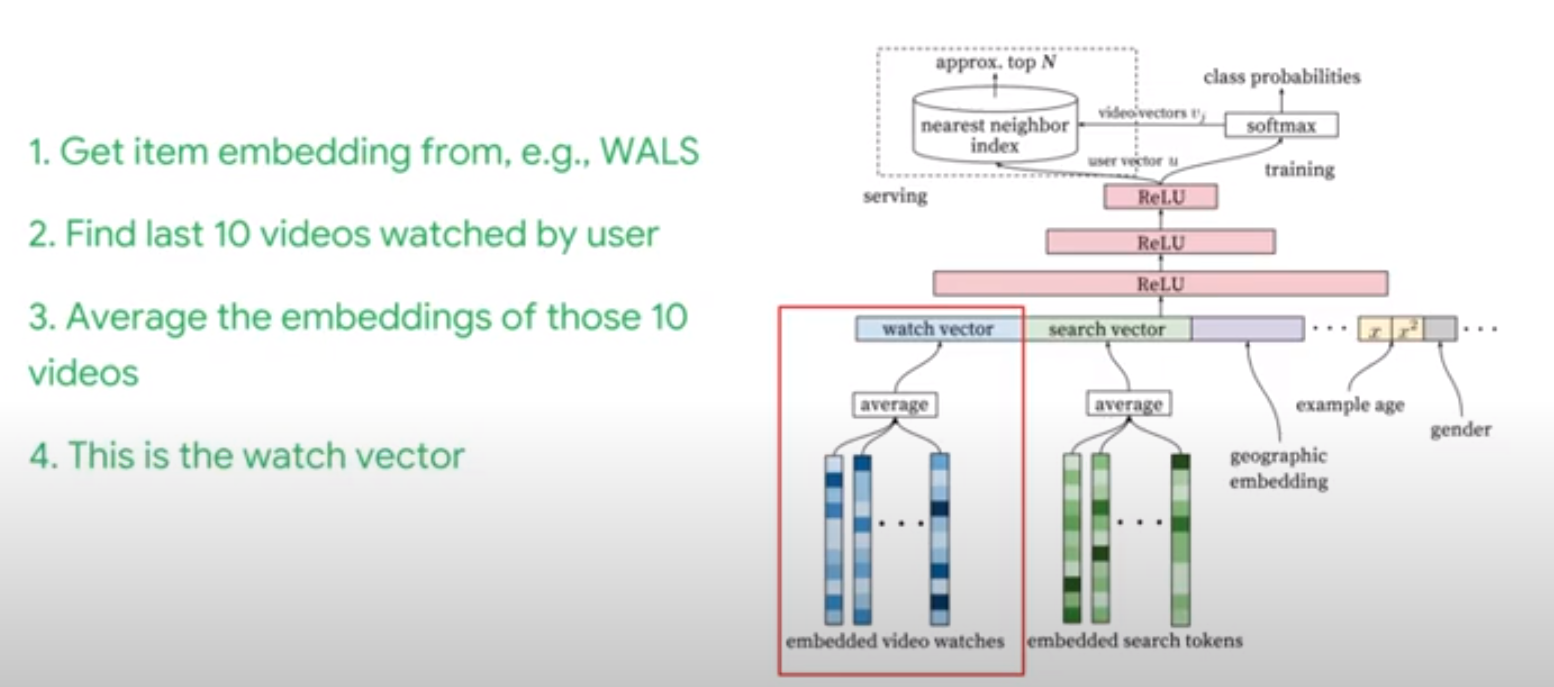
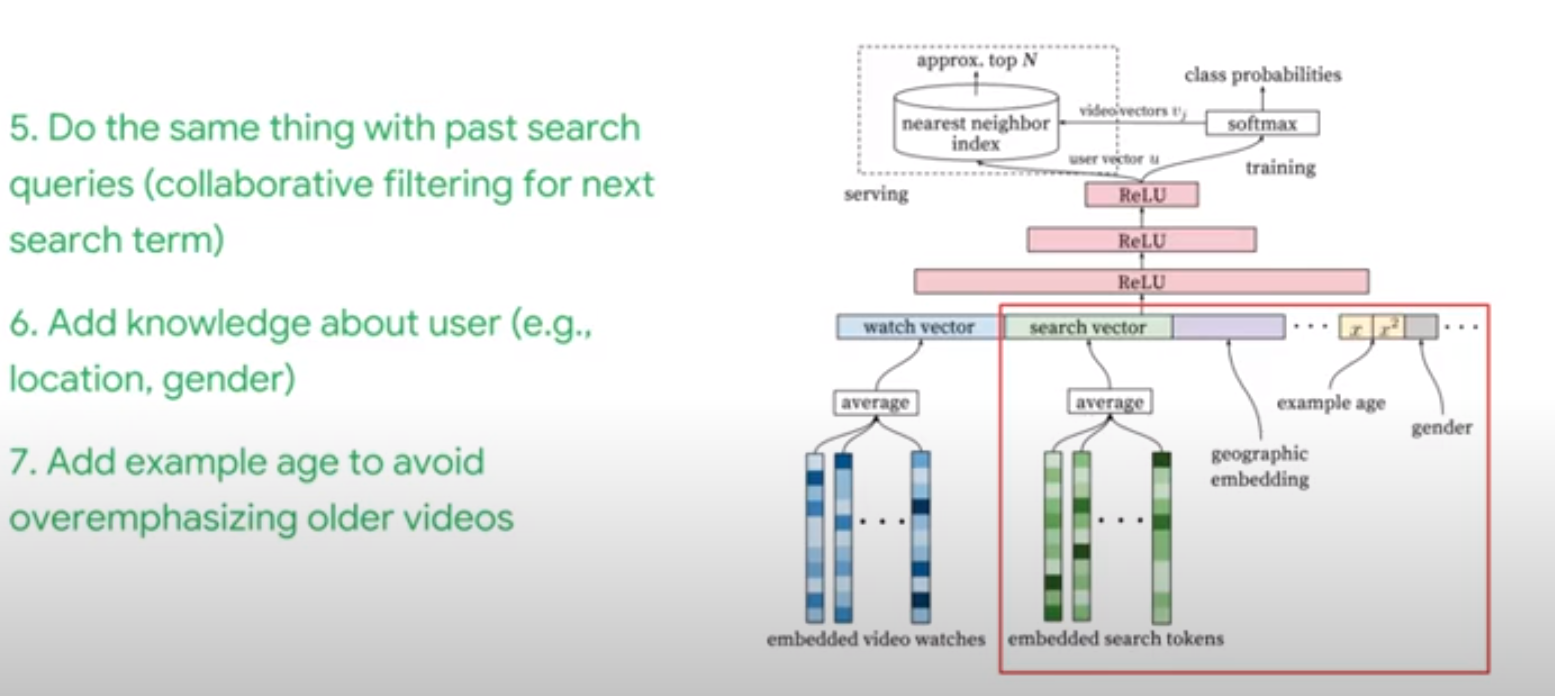
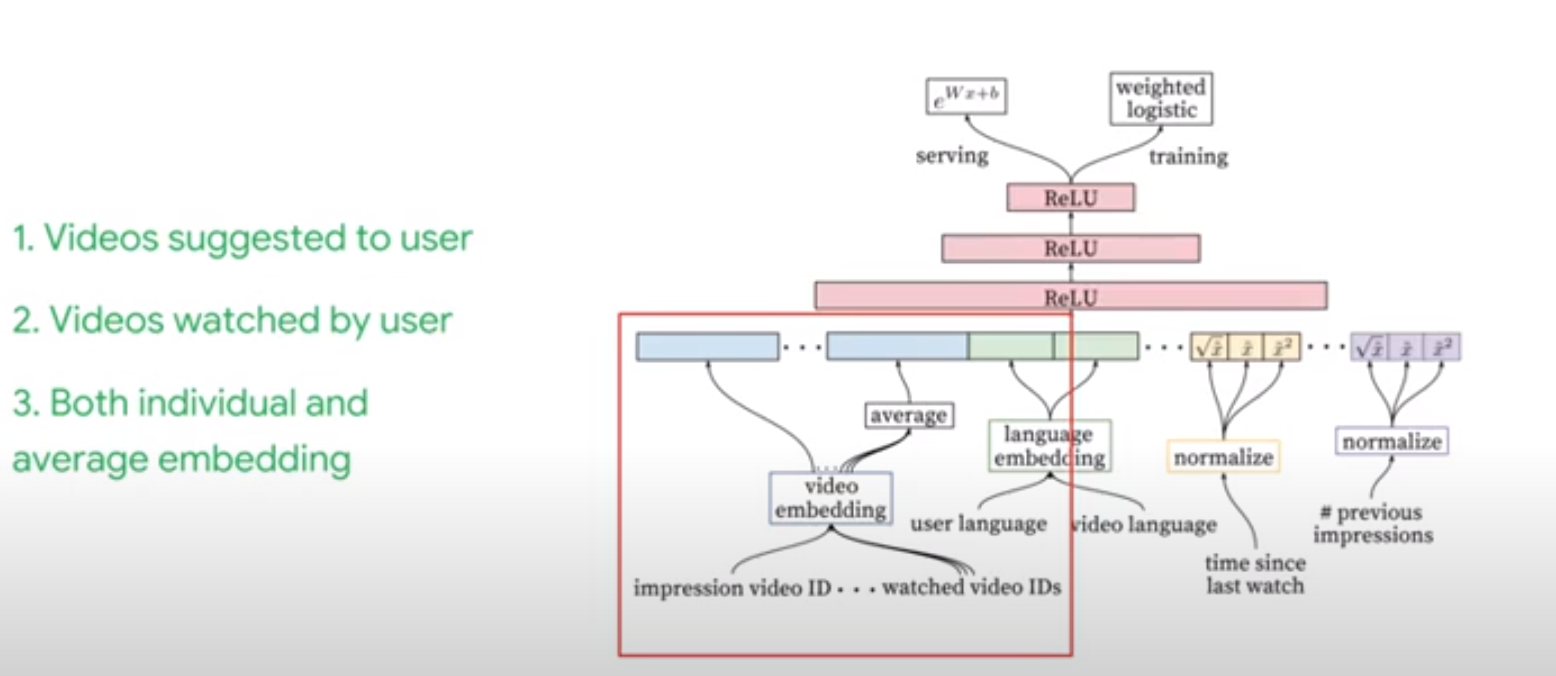
YouTube’s Recommendation System Overview